



Content:
An Introduction to Supervised Learning: Definition and Types
Understanding the Types of Supervised Learning
Common Techniques Used in Supervised Learning
How to Choose the Right Algorithm for Your Data
Conclusion
In this blog post, we will explore the concept of supervised learning in detail. We will look at what it is, how it works, and some common algorithms used in supervised learning. By the end of this post, you will have a basic understanding of how supervised learning can be used to solve real-world problems and why it is such a crucial part of machine learning.
An Introduction to Supervised Learning: Definition and Types
Supervised learning is a type of machine learning where the algorithm learns to predict outcomes based on labeled examples provided in the training data. In other words, the algorithm is provided with a set of inputs and their corresponding outputs, and the objective is to learn a mapping function that can predict the output of new inputs. The labeled examples serve as a guide to the algorithm, allowing it to adjust its parameters and optimize its performance.
Supervised learning is commonly used in classification and regression problems, where the goal is to predict a categorical or continuous variable, respectively. It is an important area of study in machine learning, as it enables us to solve a wide range of real-world problems, from medical diagnosis to stock market predictions.
Overall, supervised learning is a powerful technique that can be used to make accurate predictions based on labeled data. By understanding its definition and types, you can gain a deeper appreciation for its capabilities and how it can be applied to solve problems in your field of interest.
Understanding the Types of Supervised Learning
Understanding the Types of Supervised Learning is essential to grasp the foundations of machine learning. There are two primary types of supervised learning: regression and classification. Regression is used to predict a continuous numerical value, while classification is used to predict a categorical value.
Classification
Classification is one of the most common types of supervised learning in machine learning. The goal of classification is to assign a label or class to a new data point based on the characteristics of the data. This is achieved by using labeled data to train a model that can accurately predict the labels of new, unlabeled data.
One of the most popular classification algorithms is the k-Nearest Neighbors (KNN) algorithm. In KNN, the label of a new data point is determined based on the labels of its nearest neighbors in the training data. Here's an example of how to implement KNN in Python:
from sklearn.neighbors import KNeighborsClassifier
# Load the data
X, y = load_data()
# Create the model
knn = KNeighborsClassifier(n_neighbors=3)
# Train the model
knn.fit(X, y)
# Make predictions
predictions = knn.predict(new_data)
In this example, we first load the training data into two variables X and y. Then, we create a KNN model with n_neighbors=3, which means the label of a new data point will be determined based on the labels of its three nearest neighbors in the training data. We then train the model using the fit method and make predictions on new data using the predict method.
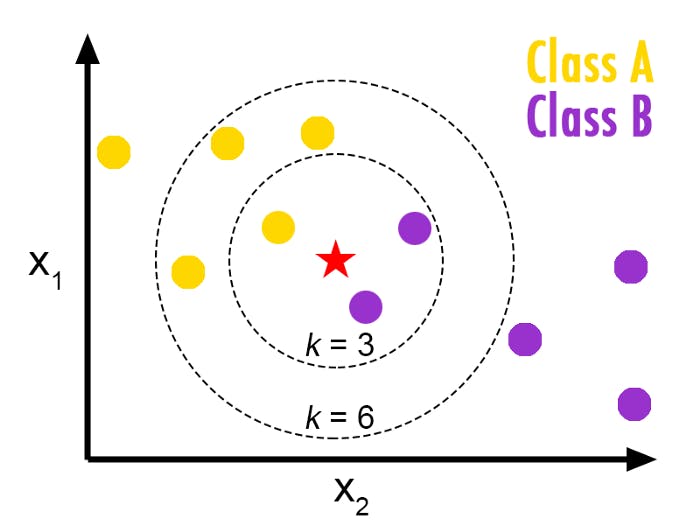
Overall, classification is a powerful tool in supervised learning that can be used in a wide range of applications, such as image recognition, spam filtering, and credit scoring.
Regression
Regression is a type of supervised learning used to predict continuous values based on the relationship between input features and an output variable. Linear regression is one of the most commonly used regression algorithms. It models the relationship between the input features and the output variable as a linear function.
Linear regression is one of the most commonly used techniques in regression problems, where the relationship between the input and output variables is assumed to be linear.
To implement linear regression, we use a linear equation of the form: y = mx + c, where y is the output variable, x is the input feature, m is the slope of the line, and c is the intercept. The goal is to find the values of m and c that minimize the difference between the predicted output and the actual output values. This process is called fitting the model to the data.
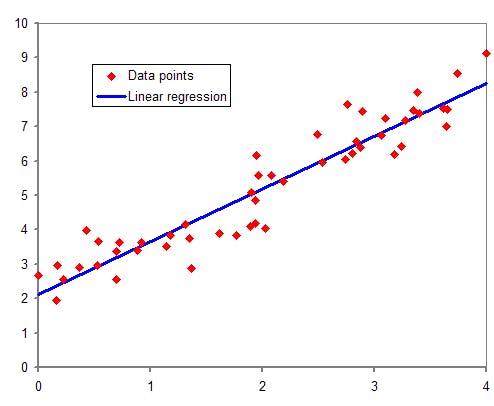
Here is an example of how to implement linear regression using the scikit-learn library in Python:
# Import necessary libraries
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load data
X, y = load_data()
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create an instance of the linear regression model
model = LinearRegression()
# Train the model on the training data
model.fit(X_train, y_train)
# Make predictions on the test data
y_pred = model.predict(X_test)
# Calculate the mean squared error of the model
mse = mean_squared_error(y_test, y_pred)
This code loads the data, splits it into training and testing sets, creates an instance of the linear regression model, trains the model on the training data, makes predictions on the test data, and calculates the mean squared error of the model.
Common Techniques Used in Supervised Learning
Supervised learning is a powerful machine-learning technique that can be used for a wide range of applications. In this article, we will explore some of the common techniques used in supervised learning. One common technique is cross-validation, which is used to estimate the performance of the model on new data. We can also use regularization techniques, such as L1 and L2 regularization, to prevent overfitting the model to the training data. Finally, we can use ensemble learning techniques, such as bagging and boosting, to improve the accuracy of the machine learning model. Let's take a closer look at these techniques and how they can be implemented in code.
Cross-validation
Cross-validation is a powerful technique used in machine learning to evaluate the performance of a model on an independent dataset. It involves partitioning the available data into several subsets or "folds", training the model on some folds and testing on the remaining folds. This process is repeated for each fold, and the performance metrics are averaged to obtain the final evaluation score.
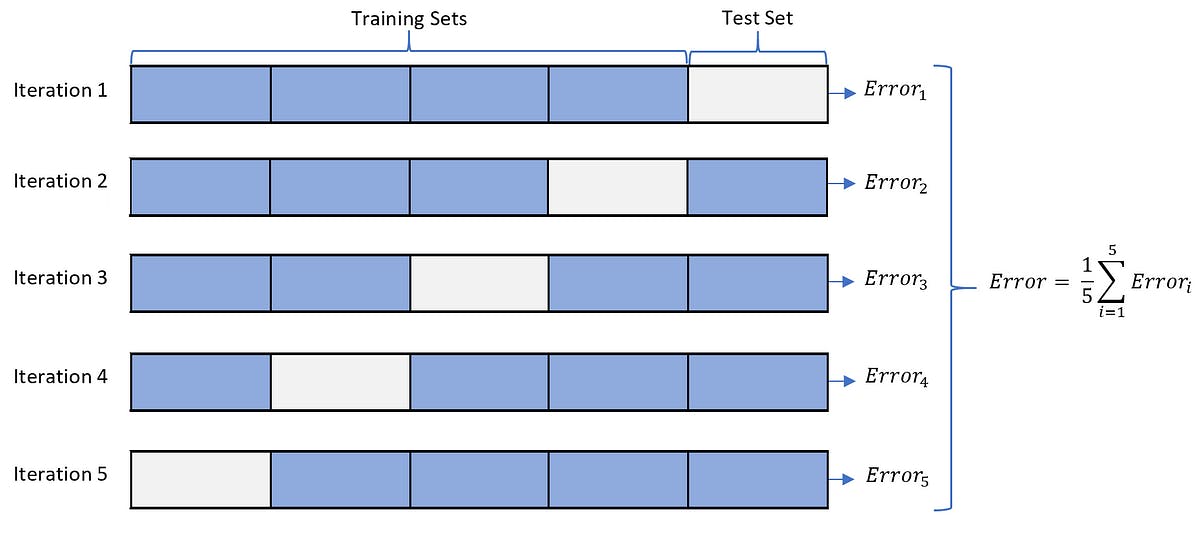
Here is an example code snippet in Python for performing 5-fold cross-validation on a linear regression model:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
# Load the dataset
X, y = load_data()
# Create a linear regression model
model = LinearRegression()
# Evaluate the model using 5-fold cross-validation
scores = cross_val_score(model, X, y, cv=5)
# Print the mean score and standard deviation
print("Cross-validation scores: ", scores)
print("Average score: ", scores.mean())
print("Standard deviation: ", scores.std())
L1 and L2 regularization
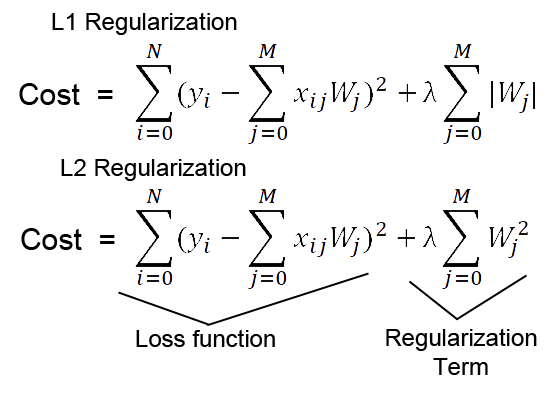
L1 and L2 regularization are techniques used in machine learning to prevent overfitting. Overfitting occurs when a model fits too closely to the training data, resulting in poor performance on new, unseen data. Regularization helps to prevent overfitting by adding a penalty term to the loss function of the model.
L1 regularization adds a penalty term to the loss function that is proportional to the absolute value of the model weights. This encourages the model to have sparse weights, meaning that some weights are set to zero, effectively removing some of the features from the model.
L2 regularization, on the other hand, adds a penalty term to the loss function that is proportional to the square of the model weights. This encourages the model to have small, non-zero weights, effectively shrinking the weights toward zero.
Here is an example of how to implement L1 and L2 regularization in Python using scikit-learn:
from sklearn.linear_model import Lasso, Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate some synthetic data
X, y = make_regression(n_samples=1000, n_features=10, noise=0.5, random_state=42)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Fit a linear regression model with L1 regularization (Lasso)
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
# Evaluate the model on the testing set
lasso_pred = lasso.predict(X_test)
lasso_mse = mean_squared_error(y_test, lasso_pred)
print("Lasso MSE: ", lasso_mse)
# Fit a linear regression model with L2 regularization (Ridge)
ridge = Ridge(alpha=0.1)
ridge.fit(X_train, y_train)
# Evaluate the model on the testing set
ridge_pred = ridge.predict(X_test)
ridge_mse = mean_squared_error(y_test, ridge_pred)
print("Ridge MSE: ", ridge_mse)
Ensemble learning techniques
Ensemble learning is a technique that involves combining multiple machine learning models to improve overall performance. Two common ensemble techniques are bagging and boosting.
Bagging: involves training multiple models on different subsets of the training data and then combining their predictions through a voting process. This helps to reduce the variance of the models and can lead to better overall performance. The BaggingClassifier in scikit-learn is an implementation of this technique.
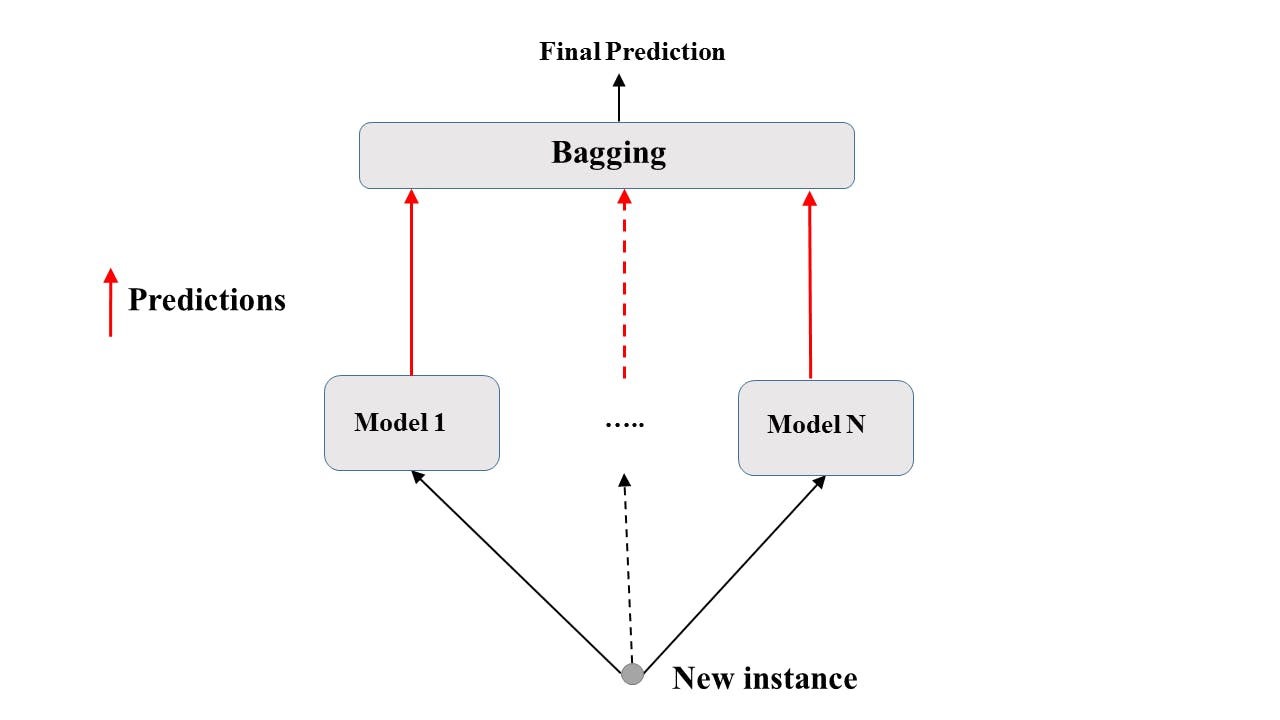
Here's an example of how to use the BaggingClassifier in Python:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
# Create a decision tree classifier
tree = DecisionTreeClassifier()
# Create a bagging classifier that uses the decision tree classifier as its base estimator
bagging = BaggingClassifier(base_estimator=tree, n_estimators=10)
# Train the bagging classifier on the training data
bagging.fit(X_train, y_train)
# Evaluate the bagging classifier on the test data
accuracy = bagging.score(X_test, y_test)
Boosting: on the other hand, involves sequentially training models on the training data, with each subsequent model attempting to correct the errors of the previous model. This can lead to better overall performance, especially when dealing with complex datasets. The AdaBoostClassifier in scikit-learn is an implementation of this technique.
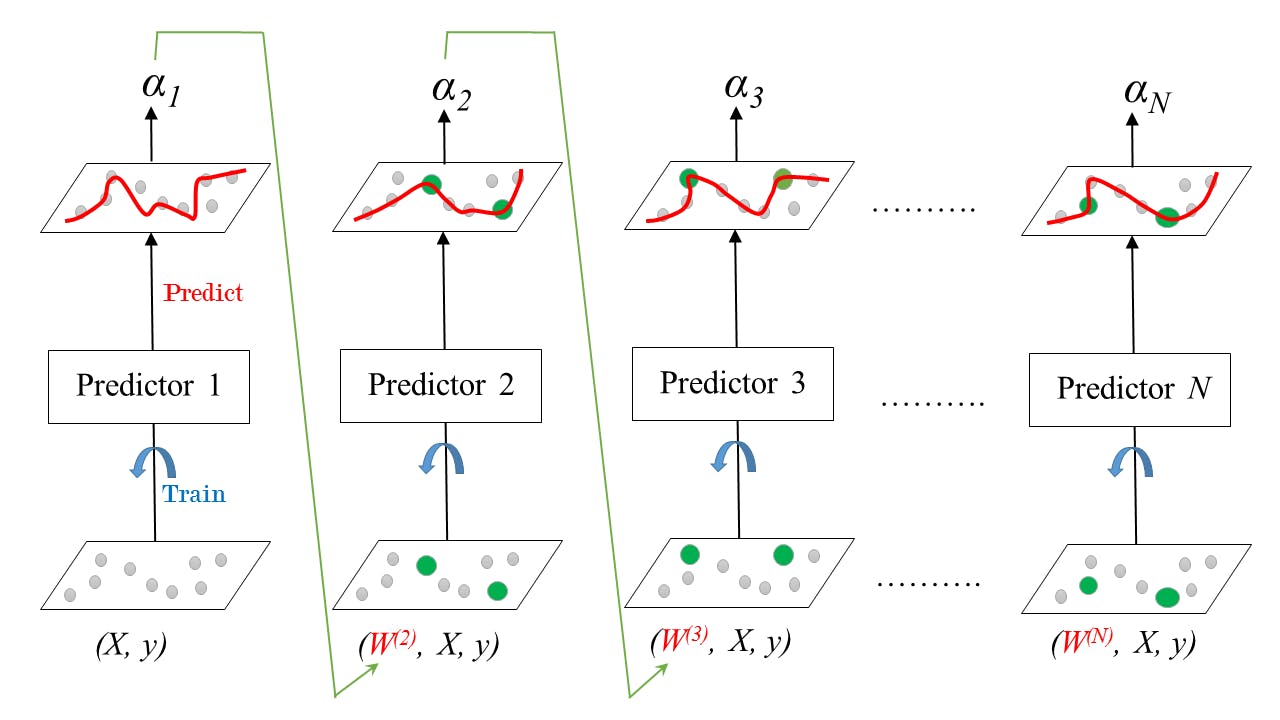
Here's an example of how to use the AdaBoostClassifier in Python:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
# Create a decision tree classifier
tree = DecisionTreeClassifier()
# Create an AdaBoost classifier that uses the decision tree classifier as its base estimator
adaboost = AdaBoostClassifier(base_estimator=tree, n_estimators=10)
# Train the AdaBoost classifier on the training data
adaboost.fit(X_train, y_train)
# Evaluate the AdaBoost classifier on the test data
accuracy = adaboost.score(X_test, y_test)
Both bagging and boosting are powerful techniques in ensemble learning that can lead to improved performance. However, they have different strengths and weaknesses, and choosing the right technique for a particular problem can require some experimentation and tuning.
How to Choose the Right Algorithm for Your Data
Choosing the right machine learning algorithm for your data is critical for achieving accurate predictions. One common approach is to try multiple algorithms and compare their performance, but this can be time-consuming and inefficient. A better approach is to understand the characteristics of different algorithms and choose the one that is best suited for your specific problem.
The first step is to determine whether you are dealing with a classification or regression problem. If the goal is to predict a categorical variable, such as whether a customer will buy a product or not, a classification algorithm should be used. If the goal is to predict a continuous variable, such as the price of a house, a regression algorithm should be used.
Next, consider the size of your dataset and the complexity of your problem. For small datasets, simple algorithms such as linear regression or decision trees may be sufficient. For larger datasets or more complex problems, ensemble methods such as random forests or gradient boosting may be more effective.
It's also important to consider the nature of your data. For example, if your data contains a mix of categorical and continuous variables, a hybrid algorithm such as support vector machines may be appropriate. If your data contains high-dimensional features, such as text or images, deep learning algorithms may be needed.
Once you have a good understanding of your problem and data, you can choose the appropriate algorithm and tune its parameters for optimal performance.
Conclusion
In conclusion, supervised learning is a powerful technique in machine learning that allows us to predict future outcomes by training on labeled data. By understanding the types of supervised learning and common techniques used in the field, we can choose the right algorithm for our data and optimize its performance through tuning. With practice and experimentation, anyone can become proficient in this exciting and rapidly-evolving field.